
В последней декаде февраля российский научно-технический центр «Модуль» стал участником ряда отраслевых выставок, прежде всего Еmbedded World 2019 и 12-й Международной авиакосмической выставки Aero India ― 2019. На каждом из этих мероприятий разработчик заключил определённые соглашения с рядом зарубежных компаний. В частности, центр заключил договор с немецкой компанией Dream Chip с целью продвижения на западные рынки систем машинного зрения на базе «нейропроцессора» NM6407. Но больший интерес вызывает свежая разработка ― гетерогенная SoC NM6408, которая была показана на индийском мероприятии.

Ряд российских источников уже окрестил разработку как мощнейший российский процессор и конкурент NVIDIA. На самом деле имеет место манипуляция фактами, хотя среди российских разработок чего-то близкого действительно нет. Пиковая производительность SoC NM6408 достигает 512 гигафлопс на операциях FP32. В пояснительной записке представители центра действительно ссылаются на гетерогенную архитектуру SoC NVIDIA Xavier и архитектуру Volta, но лишь с целью проиллюстрировать пример смешанных архитектур. По факту 512 гигафлопс ― это уровень графики GPU Maxwell в составе SoC NVIDIA Tegra X1 пятилетней давности.
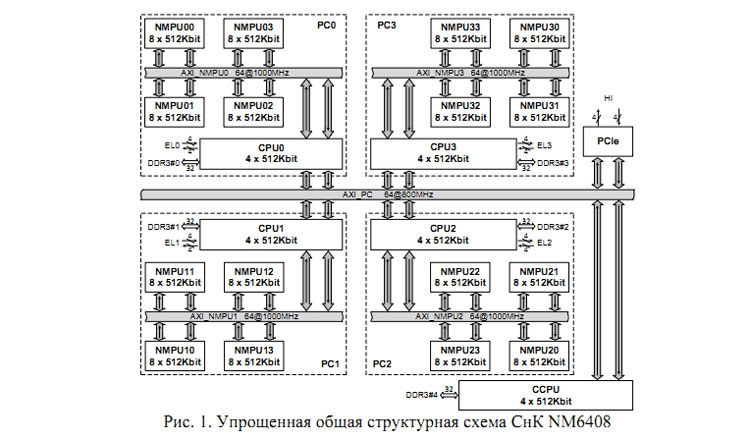
Как и в случае NVIDIA Xavier, SoC NM6408 состоит из ядер компании ARM, но вместо ядер CUDA использует фирменные векторные ядра NeuroMatrix НТЦ «Модуль». В общем случае решение состоит из пяти ядер ARM Cortex-A5 и 16 векторных ядер NeuroMatrix (NMC4). Сборка разбита на четыре кластера, каждый из которых управляется своим ядром ARM Cortex-A5 на частоте 800 МГц. В состав каждого кластера входит по 4 векторных ядра NMC4 на частоте 1 ГГц. Производительность 512 гигафлопс ― это вычисления с одинарной точностью (FP32). Разрядность выполнения векторных операций может меняться (уменьшаться), что приведёт к росту производительности в случае FP16, FP8 и FP4. Операции с двойной точностью также доступны для обработки, но тогда скорость работы для FP64 будет снижена до 128 гигафлопс.
Четыре ядра ARM Cortex-A5 из кластеров имеют кеш-память команд и данных по 32 Кбайт, а пятое ядро, осуществляющее общее управление, дополнительно располагает кеш-памятью L2 объёмом 512 Кбайт. Кроме этого ядра располагают внутренней иерархической памятью общим объёмом 9,25 Мбайт (74 Мбит). Для обращения к системной памяти предусмотрено пять интерфейсов DDR3 с пропускной способностью 6,4 Гбит/с каждый. В организации многопроцессорных конфигураций помогут четыре дуплексных высокоскоростных коммуникационных порта с пропускной способностью 2 Гбит/с в каждом направлении. В наличии интерфейсы PCIe2.0 x4, порты Ethernet 10/100, SPI и GPIO.
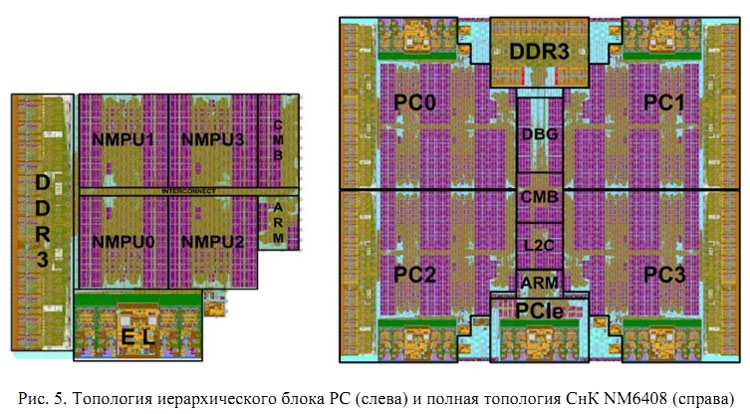
Решение выпускается с использованием 28-нм техпроцесса (скорее всего ― на линиях TSMC, но официального подтверждения этому нет). Площадь кристалла 83 мм2. Число транзисторов ― 1,05 млрд. Корпус ― BGA 1444, шаг выводов 1 мм, 40 × 40 мм FlipСhip. Максимальная потребляемая мощность не более 35 Вт. Сборка ориентирована на первичную обработку сигналов и работу с многослойными нейронными сетями. Это машинное обучение и элементы ИИ.
